
Tackling Biases In or Using Generative AI @ JSIC'24
Tackling Biases In or Using Generative AI
Dec 4, 2024
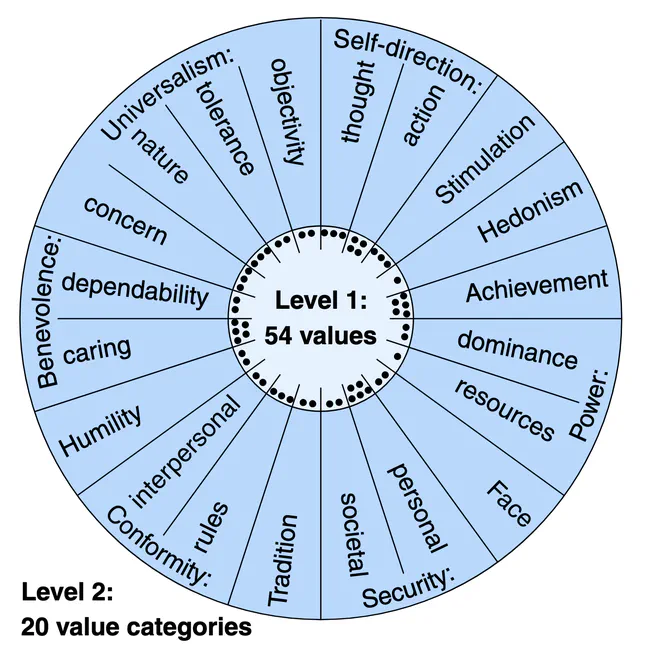
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
We've created the Touché23-ValueEval dataset, a large collection of over 9,300 arguments annotated with 54 human values, to help develop methods for analyzing the values that make arguments persuasive. Our dataset, which more than doubles the size of its predecessor, has already been used to achieve state-of-the-art results in identifying human values behind arguments, and has shown promising performance with large language models like Llama-2-7B.
May 1, 2024
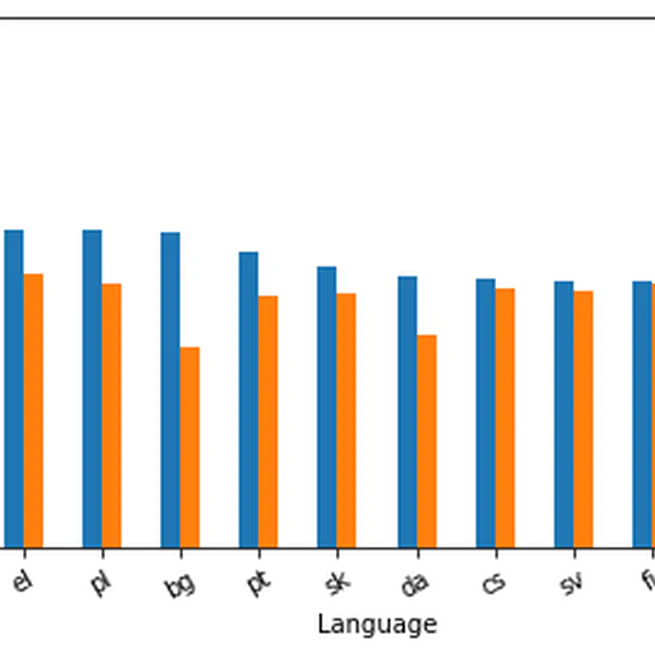
Multilingual Multi-Target Stance Recognition in Online Public Consultations
We've developed a machine learning approach to automatically recognize the opinions of citizens in online public consultations, using three datasets to train a model that can classify stances on various topics. Our work experiments with different methods, including self-supervised learning, and makes several annotated datasets available for others to use. This work was used in the Touché shared task of CLEF 2023.
Apr 1, 2023
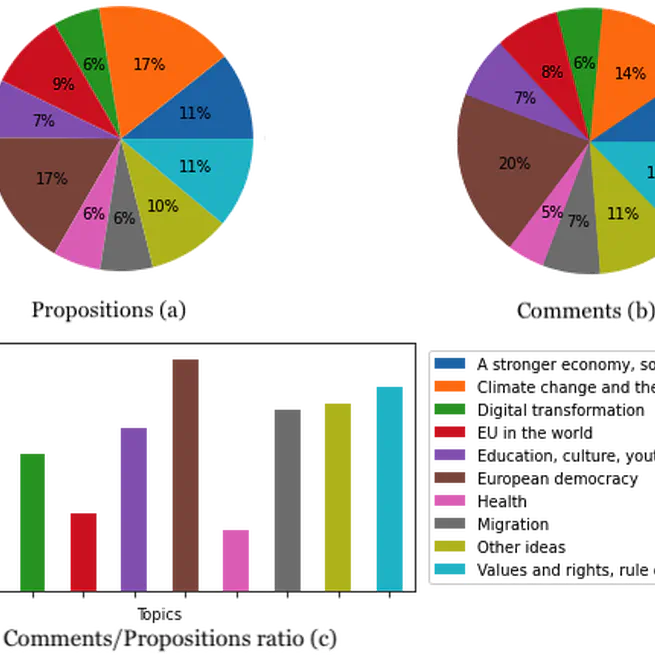
CoFE: A New Dataset of Intra-Multilingual Multi-target Stance Classification from an Online European Participatory Democracy Platform
A new dataset for Stance Recognition using data from the Participatory Democracy platform of the Conference for the Future of Europe. This dataset contains highly-multilingual interactions, as the platform used Machine Translation, in the sense that users interacts in using their (different) native languages in the same thread.
Nov 1, 2022
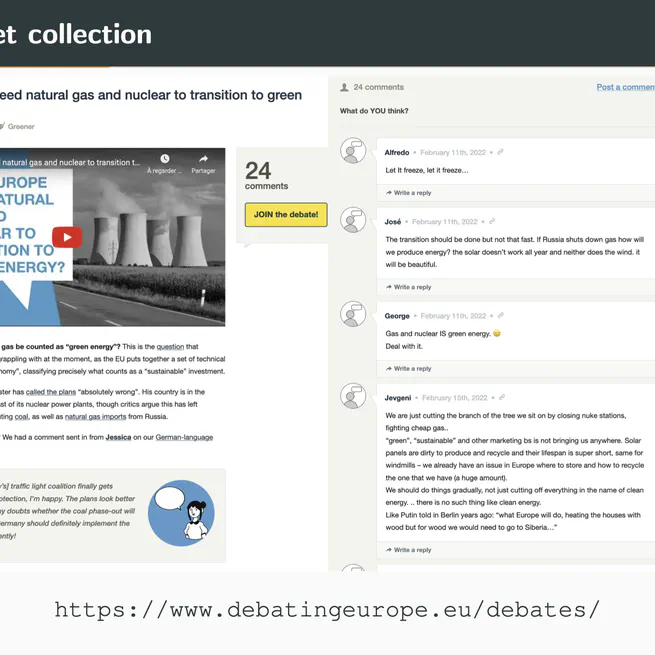
Debating Europe: A Multilingual Multi-Target Stance Classification Dataset of Online Debates
A new dataset of 2,600 online debate comments has been created to improve stance classification models. Fine-tuning and semi-supervised learning can boost accuracy by 3.4% over a baseline model.
Jun 1, 2022