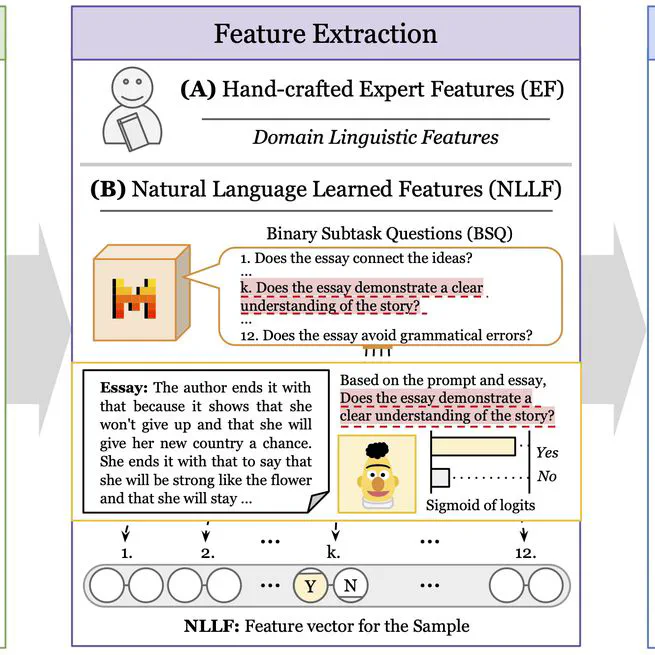
Unsupervised Automatic Short Answer Grading and Essay Scoring: A Weakly Supervised Explainable Approach
A method for unsupervised automatic short answer grading and unsupervised automatic essay scoring, that is competitive with LLM, with way less parameters, that is white box with interpretable features.
Jun 5, 2025

A Study of Nationality Bias in Names and Perplexity using Off-the-Shelf Affect-related Tweet Classifiers
We've developed a method to measure biases in AI models related to named entities from different countries, and our results show that the presence of certain country names can significantly influence predictions, such as hate speech detection and emotion analysis, with changes of up to 23% and 60% respectively! Our findings suggest that these biases are rooted in the pre-training data of language models, and we've uncovered interesting patterns that reveal how the language and country of origin can impact model predictions, with English-speaking country names having a particularly strong effect.
Nov 1, 2024
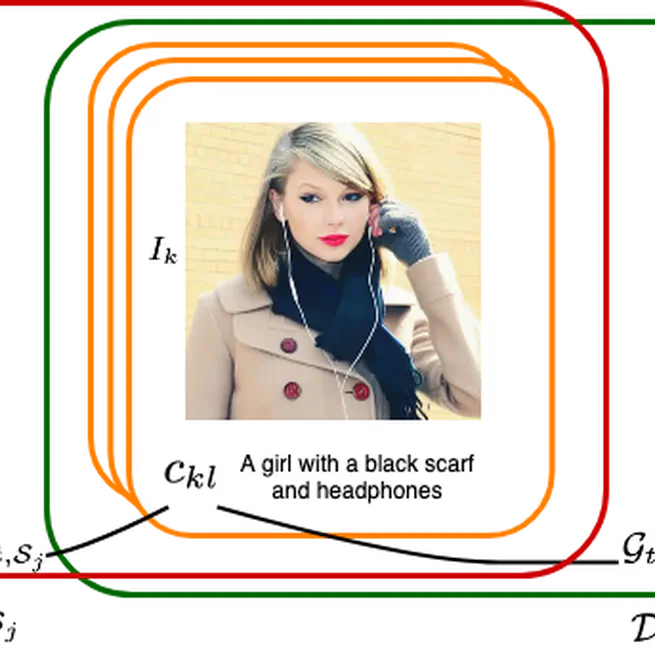
Targeted Image Data Augmentation Increases Basic Skills Captioning Robustness
TIDA is a new data augmentation method that uses text-to-image generation to create more diverse and realistic training data, helping AI models better understand complex correlations and improve their performance on tasks like gender recognition.
Dec 1, 2023
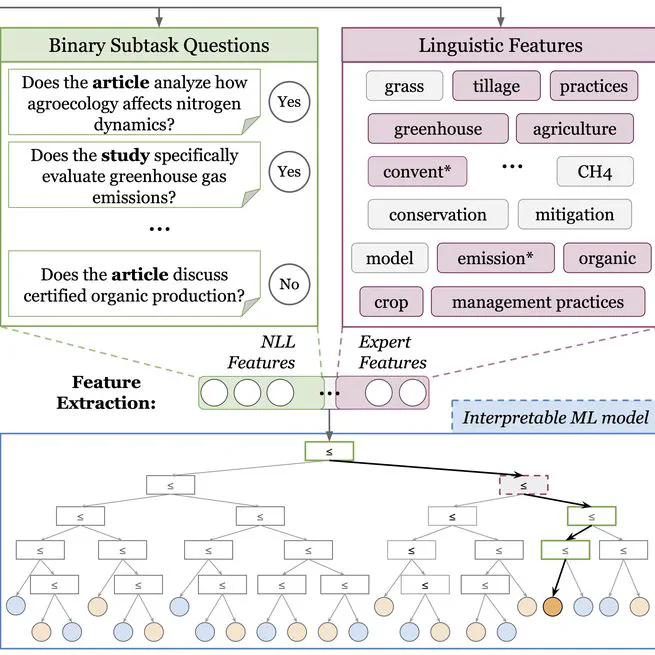
Deep Natural Language Feature Learning for Interpretable Prediction
A technique for explanability in LLM, allowing to break a complex task into subtasks formulated as binary questions in natural language, and represent any samples using the output of a binary classifier on these subtasks.
Dec 1, 2023