Targeted Image Data Augmentation Increases Basic Skills Captioning Robustness
TIDA is a new data augmentation method that uses text-to-image generation to create more diverse and realistic training data, helping AI models better understand complex correlations and improve their performance on tasks like gender recognition.
Dec 1, 2023
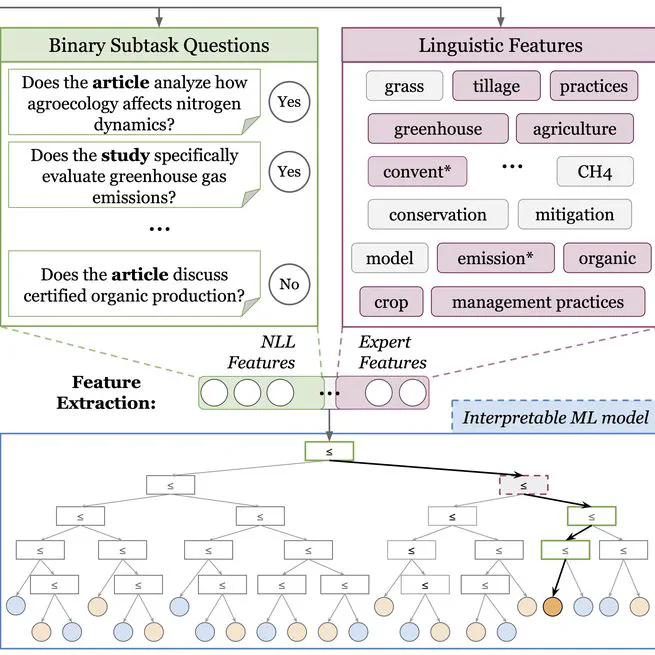
Deep Natural Language Feature Learning for Interpretable Prediction
A technique for explanability in LLM, allowing to break a complex task into subtasks formulated as binary questions in natural language, and represent any samples using the output of a binary classifier on these subtasks.
Dec 1, 2023
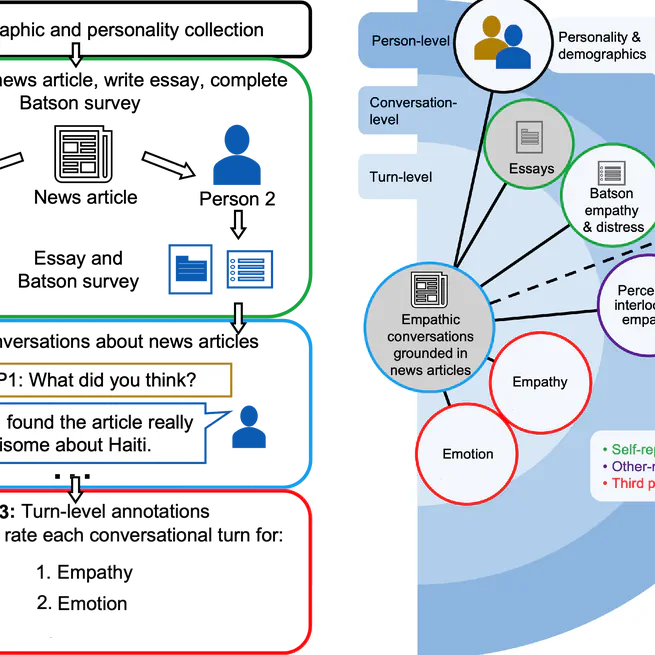
Findings of WASSA 2023 Shared Task on Empathy, Emotion and Personality Detection in Conversation and Reactions to News Articles
Findings of the shared task on Empathy, Personality, and Emotion Detection from the WASSA workshop @ ACL.
Jul 1, 2023
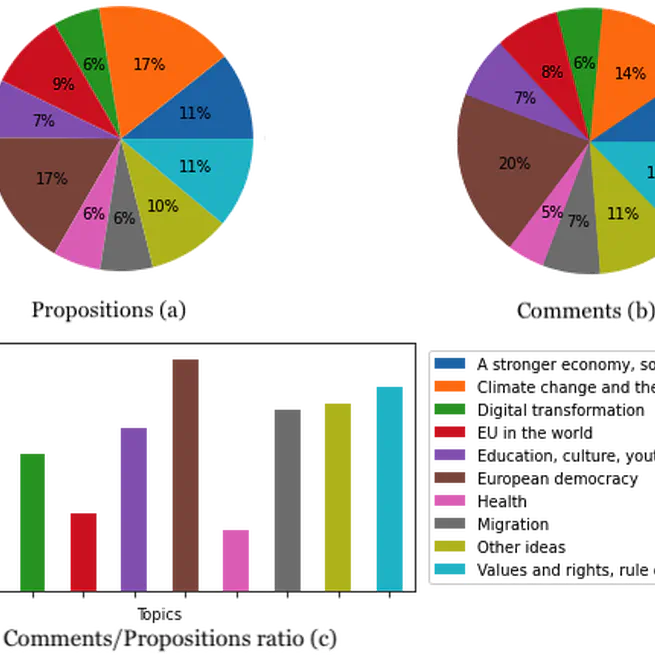
CoFE: A New Dataset of Intra-Multilingual Multi-target Stance Classification from an Online European Participatory Democracy Platform
A new dataset for Stance Recognition using data from the Participatory Democracy platform of the Conference for the Future of Europe. This dataset contains highly-multilingual interactions, as the platform used Machine Translation, in the sense that users interacts in using their (different) native languages in the same thread.
Nov 1, 2022
Opinions in Interactions : New Annotations of the SEMAINE Database
We've added new opinion annotations to the SEMAINE dataset, which captures dyadic interactions between humans and virtual agents, resulting in a rich dataset with over 73,000 words and 6 hours of conversation. Our annotations and proposed baseline model using RoBERTa embeddings achieve promising results, with a F1-score of 0.72, making it a valuable resource for opinion detection in human-computer interactions.
Jun 1, 2022
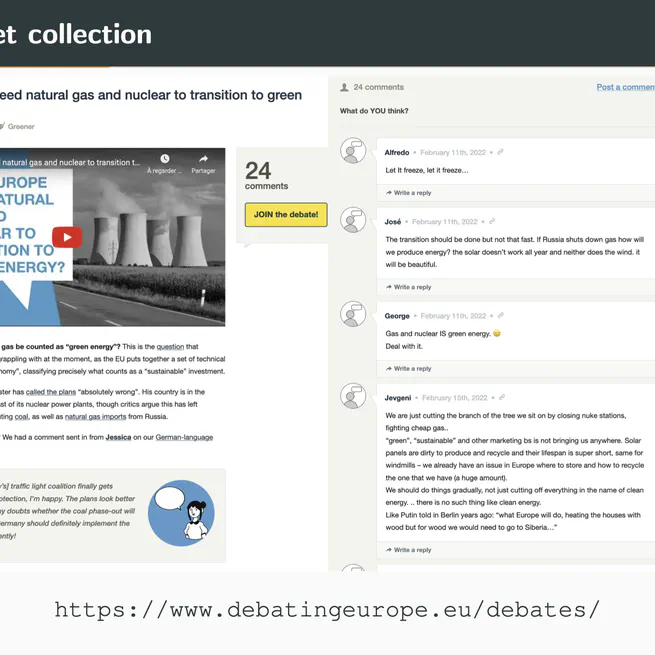
Debating Europe: A Multilingual Multi-Target Stance Classification Dataset of Online Debates
A new dataset of 2,600 online debate comments has been created to improve stance classification models. Fine-tuning and semi-supervised learning can boost accuracy by 3.4% over a baseline model.
Jun 1, 2022
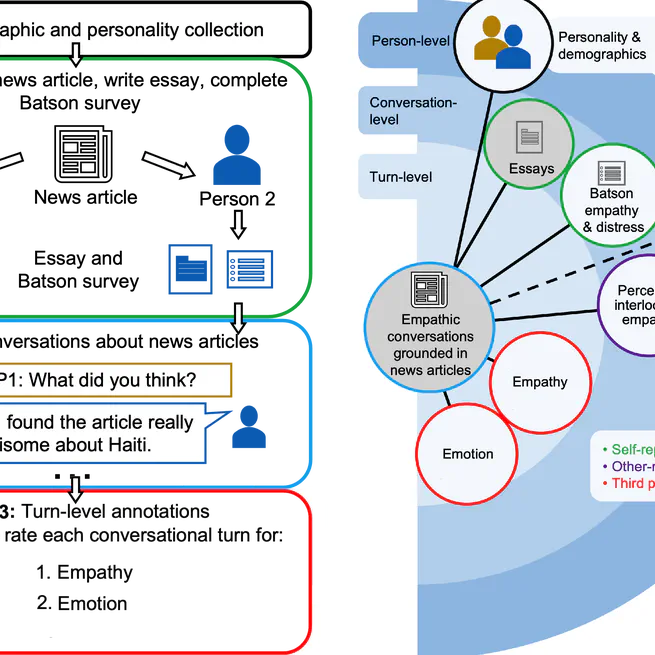
WASSA 2022 Shared Task: Predicting Empathy, Emotion and Personality in Reaction to News Stories
Findings of the shared task on Empathy, Personality, and Emotion Detection from the WASSA workshop @ ACL.
May 1, 2022
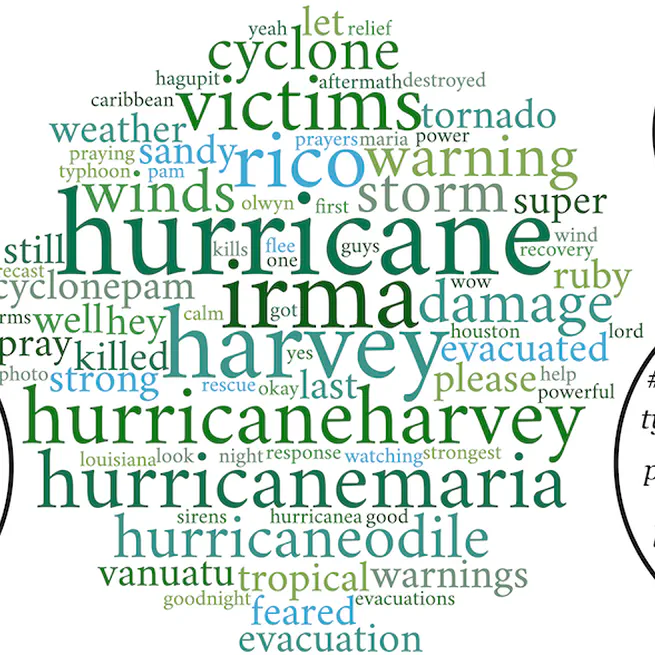
How does a Pre-Trained Transformer Integrate Contextual Keywords? Application to Humanitarian Computing
It is possible to integrate textual metadata into transformers in order to help the model improve its performances. We show the model uses the semantics of the keyword metadata analyzing the attention interaction between the metadata and the text to classify. We applied this to a humanitarian classification task over tweets, using the disaster event type as context, and finally show this method is also useful to caracterize a new event like a hurricane in a data-driven way.
May 1, 2021
Improving Sentiment Analysis over non-English Tweets using Multilingual Transformers and Automatic Translation for Data-Augmentation
We propose a technique to leverage machine translation for multilingual sentiment analysis. Appart from English, which has better models and more ressources, it is useful to translate all the tweets from every language to all the other languages and train a multilingual model over this new augmented dataset.
Dec 1, 2020