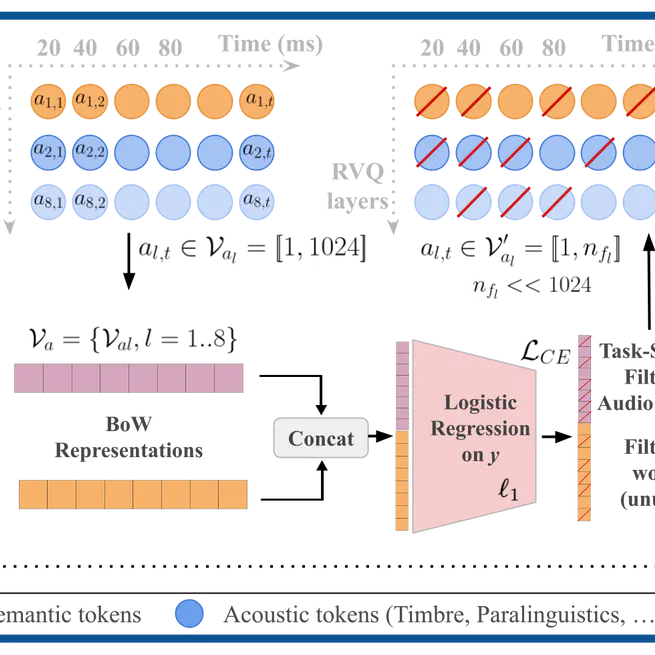
A Simple Method to Enhance Pre-trained Language Models with Speech Tokens for Classification
This work goes directly in the context of my Fondecyt de Iniciacion🗣️💬🤖 project.
Dec 10, 2025
Adapting Bias Evaluation to Domain Contexts using Generative Models
This work goes directly in the context of the XenophoBias🏳️🌈 project.
Aug 25, 2025

StandUp4AI: A New Multilingual Dataset for Humor Detection in Stand-up Comedy Videos
StandUp4AI is a new multimodal dataset for humor detection, featuring over 330 hours of stand-up comedies in seven languages. This dataset surpasses existing ones in size and diversity, and experiments show it's a valuable resource for training models, with potential for improved performance when combined with enhanced audio speech recognition methods.
Aug 5, 2025

Shaping Fine-Tuning of Geospatial Foundation Models: Effects of Label Availability and Temporal Resolution
This work goes directly in the context of the DeepCrop🛰️🌾🌽 and CopernicusLAC🛰️🇪🇺 projects.
Jul 25, 2025
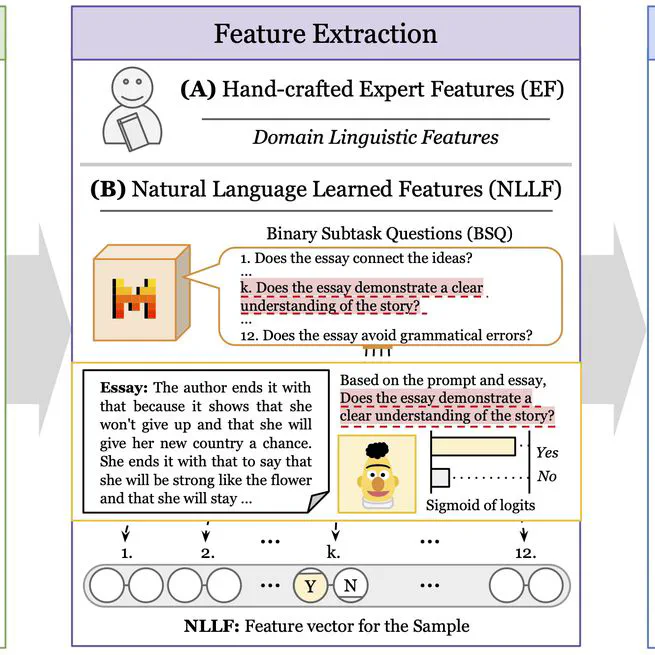
Unsupervised Automatic Short Answer Grading and Essay Scoring: A Weakly Supervised Explainable Approach
A method for unsupervised automatic short answer grading and unsupervised automatic essay scoring, that is competitive with LLM, with way less parameters, that is white box with interpretable features.
Jun 5, 2025

A Study of Nationality Bias in Names and Perplexity using Off-the-Shelf Affect-related Tweet Classifiers
We've developed a method to measure biases in AI models related to named entities from different countries, and our results show that the presence of certain country names can significantly influence predictions, such as hate speech detection and emotion analysis, with changes of up to 23% and 60% respectively! Our findings suggest that these biases are rooted in the pre-training data of language models, and we've uncovered interesting patterns that reveal how the language and country of origin can impact model predictions, with English-speaking country names having a particularly strong effect.
Nov 1, 2024
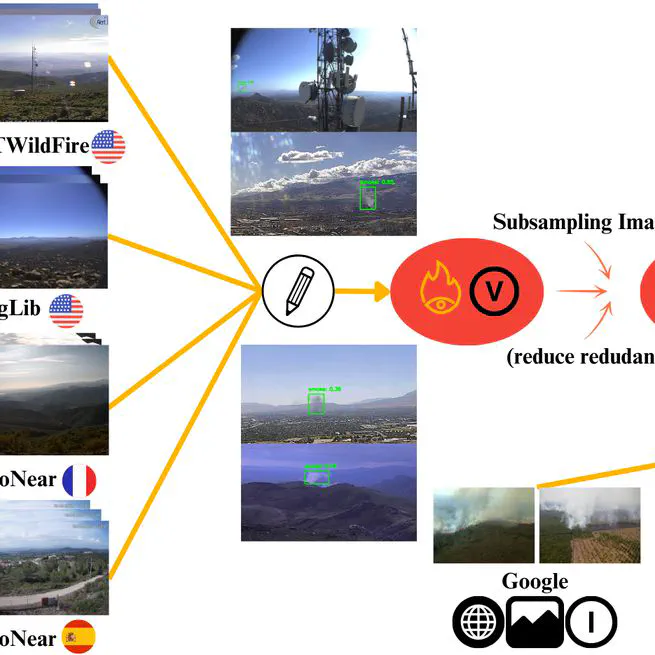
(Preprint) Scrapping The Web For Early Wildfire Detection: A New Annotated Dataset of Images and Videos of Smoke Plumes In-the-wild
PyroNear-2024 is a new dataset for smoke plume detection, featuring 150,000 annotations on 50,000 images and videos of 400 wildfires from France, Spain, and the US. This dataset surpasses existing ones in size and diversity, and experiments show it's a challenging but valuable resource for training models, with potential for improved performance when combined with other datasets.
Oct 1, 2024
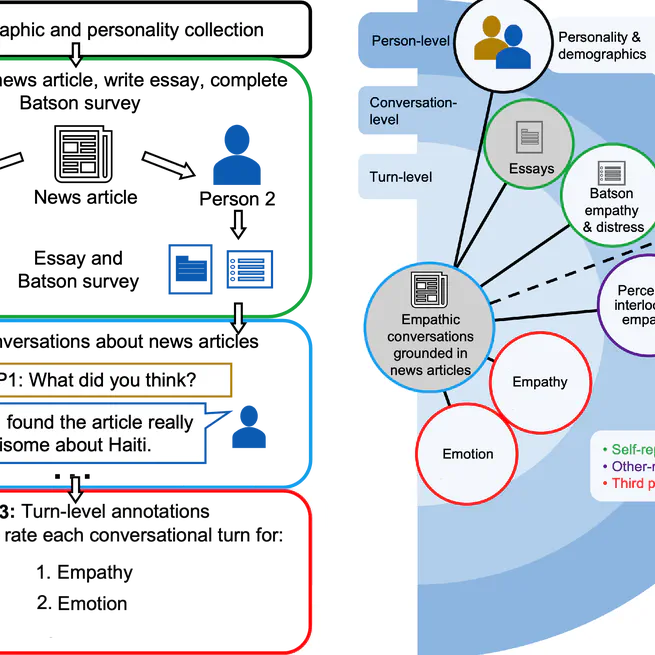
Findings of WASSA 2024 Shared Task on Empathy and Personality Detection in Interactions
Findings of the shared task on Empathy, Personality, and Emotion Detection from the WASSA workshop @ ACL.
Jul 1, 2024
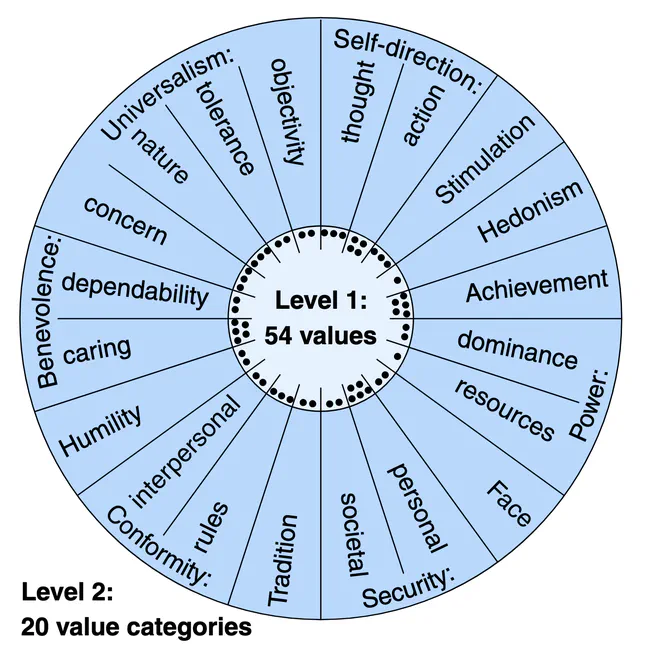
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
We've created the Touché23-ValueEval dataset, a large collection of over 9,300 arguments annotated with 54 human values, to help develop methods for analyzing the values that make arguments persuasive. Our dataset, which more than doubles the size of its predecessor, has already been used to achieve state-of-the-art results in identifying human values behind arguments, and has shown promising performance with large language models like Llama-2-7B.
May 1, 2024

Are Text Classifiers Xenophobic? A Country-Oriented Bias Detection Method with Least Confounding Variables
Current bias detection methods in machine learning have their own biases and limitations, so we've developed a new approach that directly tests fine-tuned classifiers on real-world data to identify potential biases. Our method, which involves creating counterfactual examples by modifying named entities in target data, revealed significant biases in multilingual models, including sentiment analysis and stance recognition models, and shed light on the complex interactions between names, languages, and model predictions. Current models tend to prefer names from the countries speaking the language of the sentence, impulsing for the name IA Xenophobia.
May 1, 2024