A Simple Method to Enhance Pre-trained Language Models with Speech Tokens for Classification
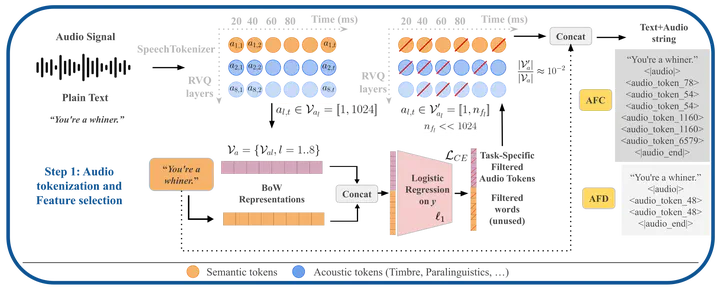 The Step one of our method consists in audio token selection pipeline based on an $\ell_1$ logistic regression using Bag-of-Word representation. This results on fewer Audio Tokens selected for a specific task.
The Step one of our method consists in audio token selection pipeline based on an $\ell_1$ logistic regression using Bag-of-Word representation. This results on fewer Audio Tokens selected for a specific task.This work goes directly in the context of my Fondecyt de Iniciacion🗣️💬🤖 project.