The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
May 1, 2024·,,,,, ,,,,,,,·
0 min read
,,,,,,,·
0 min read
Nailia Mirzakhmedova
Johannes Kiesel
Milad Alshomary
Maximilian Heinrich
Nicolas Handke
Xiaoni Cai
Valentin Barriere
Doratossadat Dastgheib
Omid Ghahroodi
MohammadAli SadraeiJavaheri
Ehsaneddin Asgari
Lea Kawaletz
Henning Wachsmuth
Benno Stein
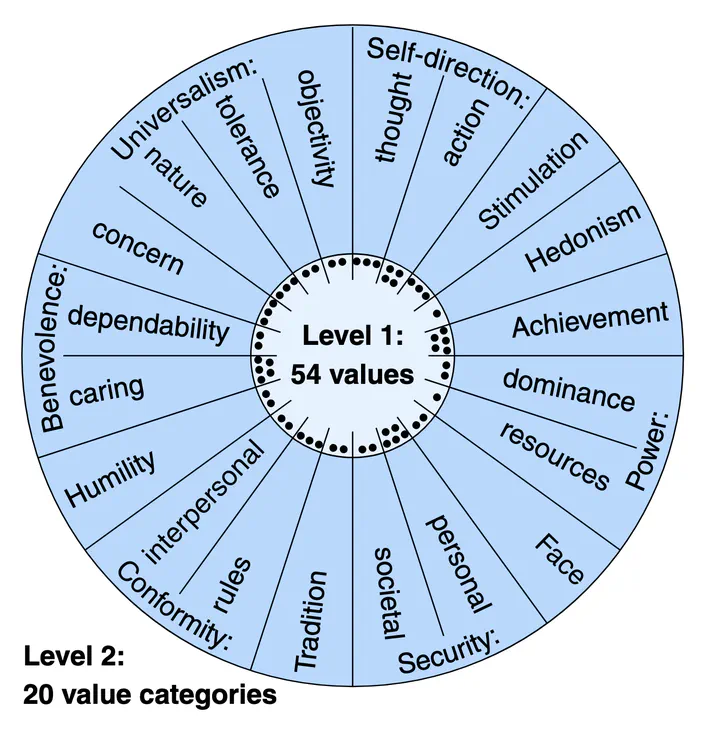 The employed value taxonomy of 20 value categories and their associated 54 values
The employed value taxonomy of 20 value categories and their associated 54 valuesAbstract
While human values play a crucial role in making arguments persuasive, we currently lack the necessary extensive datasets to develop methods for analyzing the values underlying these arguments on a large scale. To address this gap, we present the Touché23-ValueEval dataset, an expansion of the Webis-ArgValues-22 dataset. We collected and annotated an additional 4780 new arguments, doubling the dataset’s size to 9324 arguments. These arguments were sourced from six diverse sources, covering religious texts, community discussions, free-text arguments, newspaper editorials, and political debates. Each argument is annotated by three crowdworkers for 54 human values, following the methodology established in the original dataset. The Touché23-ValueEval dataset was utilized in the SemEval 2023 Task 4. ValueEval: Identification of Human Values behind Arguments, where an ensemble of transformer models demonstrated state-of-the-art performance. Furthermore, our experiments show that a fine-tuned large language model, Llama-2-7B, achieves comparable results.
Type
Publication
In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)