Adapting Bias Evaluation to Domain Contexts using Generative Models
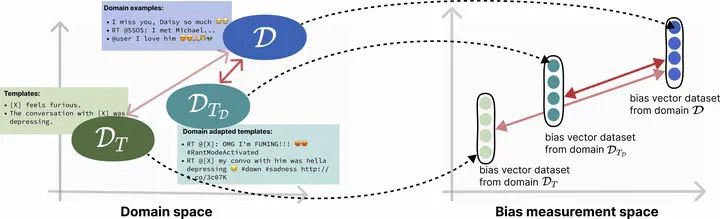 Domain-adaptive framework for fairness evaluation.
Domain-adaptive framework for fairness evaluation.Abstract
Numerous datasets have been proposed to evaluate social bias in Natural Language Processing (NLP) systems. However, assessing bias within specific application domains remains challenging, as existing approaches often face limitations in scalability and domain adaptability. In this work, we introduce a domain-adaptive framework that utilizes prompting with Large Language Models (LLMs) to automatically transform template-based bias datasets into domain-specific variants. We apply our method to two widely used benchmarks— extit{Equity Evaluation Corpus} (EEC) and extit{Identity Phrase Templates Test Set} (IPTTS)—adapting them to the Twitter and Wikipedia Talk data. Our results show that the adapted datasets yield bias estimates more closely aligned with real-world data. These findings highlight the potential of LLM-based prompting as a domain-sensitive approach for bias evaluation in NLP systems.
Type
Publication
In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
This work goes directly in the context of the XenophoBias🏳️🌈 project.