Unsupervised Automatic Short Answer Grading and Essay Scoring: A Weakly Supervised Explainable Approach
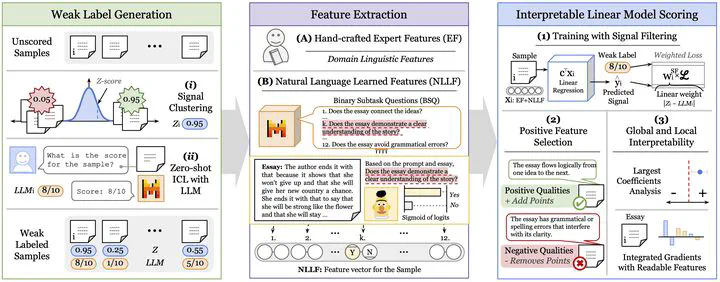 Full process. Phase 1, Generation of Weak Labels using Unsupervised methods (Signal Clustering or through an LLM). Phase 2 domain Expert Features (EFs) extraction and Natural Language Learned Features (NLLFs) obtained from answers to Binary Subtask Questions (BSQs). Phase 3, feature selection, interpretable model training and analysis.
Full process. Phase 1, Generation of Weak Labels using Unsupervised methods (Signal Clustering or through an LLM). Phase 2 domain Expert Features (EFs) extraction and Natural Language Learned Features (NLLFs) obtained from answers to Binary Subtask Questions (BSQs). Phase 3, feature selection, interpretable model training and analysis.Abstract
Automatic Short Answer Grading (ASAG) refers to automated scoring of open-ended textual responses to specific questions, both in natural language form. In this paper, we propose a method to tackle this task in a setting where annotated data is unavailable. Crucially, our method is competitive with the state-of-the-art while being lighter and interpretable. We crafted a unique dataset containing a highly diverse set of questions and a small amount of answers to these questions; making it more challenging compared to previous tasks. Our method uses weak labels generated from other methods proven to be effective in this task, which are then used to train a white-box (linear) regression based on a few interpretable features. The latter are extracted expert features and learned representations that are interpretable per se and aligned with manual labeling. We show the potential of our method by evaluating it on a small annotated portion of the dataset, and demonstrate that its ability compares with that of strong baselines and state-of-the-art methods, comprising an LLM that in contrast to our method comes with a high computational price and an opaque reasoning process. We further validate our model on a public Automatic Essay Scoring dataset in English, and obtained competitive results compared to other unsupervised baselines, outperforming the LLM. To gain further insights of our method, we conducted an interpretability analysis revealing sparse weights in our linear regression model, and alignment between our features and human ratings.
Type
Publication
In Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025)