CoFE: A New Dataset of Intra-Multilingual Multi-target Stance Classification from an Online European Participatory Democracy Platform
Nov 1, 2022· ,,·
0 min read
,,·
0 min read
Valentin Barriere
Guillaume Jacquet
Léo Hemamou
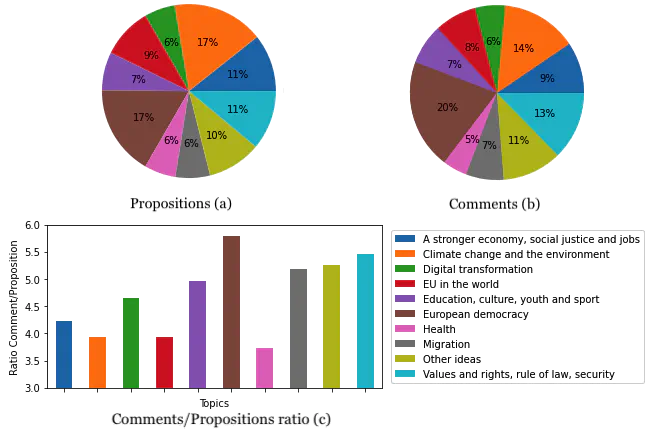 Topics distribution in the propositions, comments, and the ratio of comments over propositions regarding the differnt topics.
Topics distribution in the propositions, comments, and the ratio of comments over propositions regarding the differnt topics.Abstract
Stance Recognition over proposals is the task of automatically detecting whether a comment on a specific proposal is in favor of this proposal, against this proposal or that neither inference is likely. The dataset that we propose to use is an online debating platform inaugurated in 2021, where users can submit proposals and comment over proposals or over other comments. It contains 4.2k proposals and 20k comments focused on various topics. Every comment and proposal can come written in another language, with more than 40% of the proposal/comment pairs containing at least two languages, creating a unique intra-multilingual setting. A portion of the data (more than 7k comment/proposal pairs, in 26 languages) was annotated by the writers with a self-tag assessing whether they are in favor or against the proposal. Another part of the data (without self-tag) has been manually annotated: 1206 comments in 6 morphologically different languages (fr, de, en, el, it, hu) were tagged, leading to a Krippendorff’s α of 0.69. This setting allows defining an intra-multilingual and multi-target stance classification task over online debates.
Type
Publication
In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing